软件技术基础与开发 线性表索引存储结构与数组及稀疏矩阵存储方法
软件技术基础与开发:线性表索引存储结构与数组及稀疏矩阵存储方法
引言
在软件技术基础与开发课程中,数据结构的存储方法是核心内容之一。本章将重点探讨线性表的索引存储结构,以及数组和稀疏矩阵的存储方法。这些基础概念是构建高效、可靠软件系统的基石,对于任何软件开发人员来说都是必备知识。
一、线性表索引存储结构
1.1 线性表的基本概念
线性表是最基本、最常用的一种数据结构,它是n个数据元素的有限序列。线性表中的数据元素可以是数字、字符、记录等,它们之间存在一对一的关系,即每个元素都有一个直接前驱和一个直接后继(除了第一个和最后一个元素)。
1.2 索引存储结构的原理
索引存储结构是一种结合了顺序存储和链式存储优点的存储方式。它通过建立索引表来提高数据访问效率,特别适用于需要频繁查找但较少插入删除操作的场景。
索引存储结构的基本思想是:
- 将数据元素分成若干块,每块内的元素可以顺序存储
- 为每块建立一个索引项,包含该块的最大关键字和块的起始地址
- 所有索引项组成索引表,通常按关键字有序排列
1.3 索引存储结构的实现方式
1.3.1 稠密索引
每个数据元素都有一个索引项,索引项按关键字有序排列。这种方式的优点是查找速度快,但需要额外的存储空间来存放索引表。
1.3.2 稀疏索引
只为每个数据块建立一个索引项,索引项包含块内最大关键字和块的起始地址。这种方式节省了存储空间,但查找时需要先在索引表中确定块的位置,再在块内顺序查找。
1.4 索引存储结构的应用场景
- 数据库系统中的索引
- 文件系统中的目录结构
- 大型数据集合的快速检索
二、数组存储方法
2.1 数组的基本概念
数组是一种线性数据结构,它由相同类型的元素组成,这些元素在内存中连续存储。数组通过下标来访问元素,支持随机访问,时间复杂度为O(1)。
2.2 一维数组的存储
一维数组在内存中按顺序连续存储。假设数组A有n个元素,每个元素占k个字节,起始地址为LOC(A[0]),则元素A[i]的地址为:
LOC(A[i]) = LOC(A[0]) + i × k
2.3 多维数组的存储
多维数组在内存中通常有两种存储方式:
2.3.1 行优先存储
按行顺序存储数组元素。对于m×n的二维数组A,元素A[i][j]的地址为:
LOC(A[i][j]) = LOC(A[0][0]) + (i × n + j) × k
2.3.2 列优先存储
按列顺序存储数组元素。对于m×n的二维数组A,元素A[i][j]的地址为:
LOC(A[i][j]) = LOC(A[0][0]) + (j × m + i) × k
2.4 数组的优缺点
优点:
- 支持随机访问,访问效率高
- 内存连续,缓存友好
- 实现简单,易于理解
缺点:
- 大小固定,不够灵活
- 插入删除操作效率低
- 可能造成内存浪费
三、稀疏矩阵存储方法
3.1 稀疏矩阵的概念
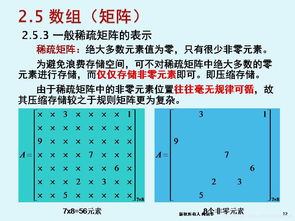
稀疏矩阵是指矩阵中绝大多数元素为零的矩阵。在实际应用中,很多大规模矩阵都是稀疏的,如网络图、微分方程离散化后的矩阵等。
3.2 稀疏矩阵的压缩存储
由于稀疏矩阵中非零元素很少,直接使用二维数组存储会浪费大量空间,因此需要采用特殊的压缩存储方法。
3.2.1 三元组顺序表
将每个非零元素表示为一个三元组(i, j, value),其中i为行号,j为列号,value为元素值。将所有三元组按行优先顺序存储在一个一维数组中。
示例:
对于稀疏矩阵:`
0 0 3 0
0 0 0 0
0 5 0 0
0 0 0 9`
三元组表示为:
(0, 2, 3)
(2, 1, 5)
(3, 3, 9)
3.2.2 行逻辑链接顺序表
在三元组顺序表的基础上,增加一个行起始位置数组,记录每行第一个非零元素在三元组表中的位置。
3.2.3 十字链表
每个非零元素用一个节点表示,节点中包含行号、列号、值,以及指向同一行中下一个非零元素的指针和指向同一列中下一个非零元素的指针。
3.3 稀疏矩阵的运算优化
采用压缩存储后,稀疏矩阵的运算需要进行相应调整:
3.3.1 转置运算
对于三元组存储的稀疏矩阵,转置运算需要重新排列三元组的顺序。可以采用快速转置算法,时间复杂度为O(n+t),其中n为列数,t为非零元素个数。
3.3.2 加法运算
两个稀疏矩阵相加时,只需处理非零元素,大大减少了计算量。
3.4 稀疏矩阵存储的应用
- 科学计算中的大型方程组求解
- 图像处理中的像素矩阵
- 社交网络中的关系矩阵
- 推荐系统中的用户-物品评分矩阵
四、基础软件开发中的实践应用
4.1 数据结构选择原则
在基础软件开发中,选择合适的数据结构存储方法至关重要:
- 分析数据特点和操作需求
- 评估时间和空间复杂度
- 考虑实现的复杂度和可维护性
- 测试不同方案的实际性能
4.2 性能优化技巧
- 合理使用缓存:利用数据局部性原理
- 避免不必要的复制:使用引用或指针传递大数据结构
- 预分配内存:减少动态内存分配的开销
- 选择合适的数据结构:根据具体场景选择数组、链表或索引结构
4.3 实际案例分析
以图像处理软件为例:
- 使用二维数组存储普通图像数据
- 对于二值图像或简单图形,可以使用稀疏矩阵存储
- 建立图像金字塔时,可以使用索引结构快速访问不同分辨率的图像
五、与展望
线性表的索引存储结构、数组和稀疏矩阵存储方法是软件技术基础中的重要内容。掌握这些基础知识不仅有助于理解更复杂的数据结构和算法,还能在实际开发中选择合适的存储方案,提高软件的性能和效率。
随着大数据和人工智能技术的发展,对这些基础存储方法的理解和应用将变得更加重要。未来的软件开发人员需要深入理解这些基础原理,并能根据具体应用场景灵活运用和优化。
课后思考题
- 比较稠密索引和稀疏索引的优缺点,分别适用于什么场景?
- 对于一个1000×1000的矩阵,其中只有10个非零元素,采用二维数组存储和稀疏矩阵存储各需要多少存储空间?
- 在设计一个文件系统时,如何利用索引存储结构提高文件检索效率?
- 在实际编程中,如何根据具体情况选择使用数组还是链表?
参考文献
- 严蔚敏,吴伟民. 数据结构(C语言版)
- Thomas H. Cormen等. 算法导论
- Robert Sedgewick. 算法
本讲义仅供课堂教学使用,转载请注明出处
如若转载,请注明出处:http://www.xshark-c.com/product/86.html
更新时间:2026-05-30 12:05:14